|
|
|
ОБ’ЄКТНО ОРІЄНТОВАНЕ ПРОГРАМУВАННЯ Електронний посібник |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Модуль 6 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6. Проєктування та
реалізація архітектури програм. забезпечення якості програмних продуктів 6.1. Проєктування
ієрархії класів. Використання UML. Особливості створення класів 6.2. Рефакторинг.
Типові архітектурні рішення та антипатерни 6.3. Обробка помилок
та виключень. Відлагодження, тестування та
профілювання
Клас, на базі якого
створюється підклас, називають надкласом, суперкласом або ж батьківським
класом. Новий клас, що розширює (extends)
батьківський клас називають підкласом або дочірнім класом. На відміну від С++, де клас
може мати кілька батьківських класів, мова програмування Java підтримує лише одинарне успадкування, тобто може
бути лише один безпосередній надклас. У надкласу звичайно може бути свій
надклас, проте також лише один безпосередній. Множинне успадкування доволі
складне у застосуванні і вимагає обережного підходу, тому творці Java вирішили відмовитися від нього. Для графічного
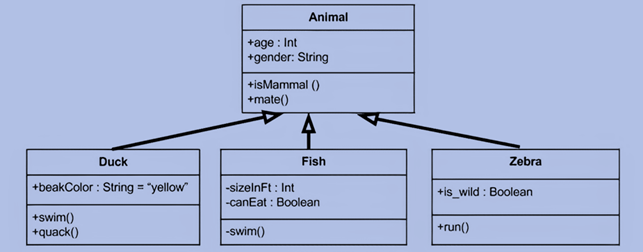
представлення ієрархії успадкування зазвичай використовують діаграму класів UML
– статичне представлення структури моделі. Вона
відображає статичні (декларативні) елементи, такі як: класи, типи даних, їх
зміст та відношення. Діаграма класів
може містити позначення для пакетів та позначення для вкладених пакетів.
Також діаграма класів може містити позначення деяких елементів поведінки,
однак їх динаміка розкривається в інших типах діаграм. Діаграма класів служить
для представлення статичної структури моделі системи в термінології класів
об'єктно орієнтованого програмування. На цій діаграмі показують класи,
інтерфейси, об'єкти й кооперації, а також їхні стосунки. Приклад діаграми
класів:
Для створення
діаграм класів прямо в середовищі NetBeans можна
скористатись плагіном easyUML, який підтримує
також кодогенерацію та зворотний інжиніринг.
Слід
зазначити, що на основі діаграми класів можна отримати лише каркасний код,
який вимагає доопрацювання. Зворотна
розробка або зворотний інжиніринг – дослідження деякого пристрою чи програми з метою
розуміння принципів роботи досліджуваного об'єкта. Найчастіше
використовується з метою створення об'єкта, за функціональністю аналогічного
досліджуваному але без точного копіювання його функцій. Зазвичай
використовується у випадках, коли розробник оригінального пристрою чи
програми не надає точних відомостей про алгоритми функціонування виробу або
будь-яким чином намагається завадити його використанню. В
нашому випадку зворотний інжиніринг полягає в побудові діаграми класів за існуючим кодом. Такі діаграми можуть слугувати
засобом контролю – відслідковування прогресу проєкту. Ще
один доступний інструмент для UML-проєктування, кодогенерації та зворотного інжинірингу – StarUML –
інструмент, який було ліцензовано під модифікованою версією GNU GPL до 2014
року, коли переписана версія 2.0.0 була випущена для бета-тестування під
власною ліцензією. У
2014 році була випущена переписана версія як запатентоване програмне
забезпечення. Заявленою метою проєкту було замінити
комерційні програми, такі як Rational Rose та Borland Together. StarUML підтримує
більшість типів діаграм, зазначених у UML 2.0 . Починаючи з версії 4.0.0 (29
жовтня 2020 р.), вона включає оглядові діаграми та діаграми взаємодії. За
допомогою плагінів StarUML
підтримує кодогенерацію та зворотний інжиніринг для
таких мов, як C/C++, C# та Java.
Слово
"рефакторинг" пішло від терміну "факторинг" в структурному програмуванні, який означав
декомпозицію програми на максимально автономні та елементарні частини. Існує
міф про те, що правильно організований процес розробки продукту методично дотримується поставлених вимог, визначає
однозначний, стабільний список обов’язків програми, і при цьому програмний
код може бути написаний майже лінійно – від початку до
закінчення, кожна ділянка – один раз написана,
відтестована й забута. Згідно з цим міфом, єдиний
випадок, коли наявний код може змінюватись, – це в процесі підтримки і
адміністрування програми, коли початкова версія продукту уже здана замовнику. Однак
реальність є дещо інакшою. Насправді код еволюціонує в
процесі розробки продукту.
Як правило, кодування, відлагодження та модульне
тестування займають в середньому 30–65% зусиль від загального часу існування проєкту (залежно від величини проєкту).
Навіть в
ході добре організованих проєктів вимоги змінюються
в середньому на 1–4% за місяць, що неминуче спричиняє зміни до програмного
коду – як дрібні, так і досить серйозні. Також,
на відміну від старіших методик розробки програмних
продуктів, де основний акцент ставився на мінімізації змін до коду, сучасна
методика вбачає великий потенціал у внесенні змін. Вона є сфокусованою на коді (code-centered)
і під час розробки можна очікувати, що код буде вдосконалюватися більше, ніж
зазвичай.
Існує
чимало прийомів (методів) рефакторингу –
Відокремлення методу (Extract Method),
відокремлення базового класу (Extract Superclass), інкапсуляція поля (Encapsulate
Field) тощо. Багато
інтегрованих середовищ розробки, зокрема Netbeans, містять вбудовані механізми рефакторингу коду. Крім інтегрованої
функціональності, існує також багато продуктів сторонніх виробників, які, як правило,
реалізовані у вигляді додатків (plugins) до
відповідного IDE. Патерни (або
шаблони) описують типові способи вирішення поширених проблем під час проєктування програм. Хоча ви можете цілком успішно
працювати, не знаючи жодного патерна, опанувавши їх,
ви отримаєте ще один потужний інструмент в свій набір професіонала. Патерни відрізняються за рівнем складності, охоплення і
деталізації проєктованої системи. Проводячи
аналогію з будівництвом, ви можете підвищити безпеку на перехресті,
встановивши світлофор, а можете замінити перехрестя цілою автомобільною
розв’язкою з підземними переходами. Низькорівневі
та найпростіші патерни – ідіоми.
Вони не дуже універсальні, позаяк мають сенс лише в рамках однієї мови
програмування. Максимально
універсальними є архітектурні патерни, які можна
реалізувати практично будь-якою мовою. Вони потрібні для проєктування
всієї програми, а не окремих її елементів. Крім цього, патерни
відрізняються і за призначенням.
Взагалі
існує 32 класичних патерни, які
відрізняються за призначенням. Поряд
з патернами існують і антипатерни.
Антипатерн, або антишаблон,
– загальний спосіб вирішення проблеми, що часто
виникає під час проєктування програмного
забезпечення, який, як правило, неефективний та зменшує продуктивність
комп'ютерної програми. Інакше кажучи, антипатерн – шкідливий і
неефективний патерн. Концепція
антипатерну є універсальною і придатна не лише для
програмної інженерії, але й для практично будь-якої сфери людської
діяльності; втім термін не набув поширення поза межами IT-індустрії. Поняття
антипатерну з'явилось тоді, коли програмісти
зрозуміли, що описувати і документувати необхідно не лише гарні ідеї, але й
погані. Правильно сформульований антипатерн
складається не лише з опису типової помилки, але й пояснює, чому таке рішення
виглядає привабливим (наприклад, економить час розробки, чи дійсно працює в
деякому обмеженому контексті), до яких негативних наслідків воно призводить,
і яким патерном бажано його замінити. Найважливіша
мета документування антипатернів – полегшити можливість розпізнавання шкідливого
рішення і успішного виправлення помилок ще на ранніх етапах роботи. Антипатерн не просто застерігає "Не
роби цього! ", а вказує інженеру на те, що він, можливо, не
усвідомлює, що рішення такого типу принесе набагато більше шкоди, ніж
користі.
У
більшості випадків рефакторинг має на меті саме
усунення антипатернів.
Прикладом
є ділення на нуль, помилки читання з файлу та мережі тощо. Іншими словами –
це помилки, які можуть виникнути під час виконання
програми. В деяких мовах
програмування необхідно заздалегідь передбачити можливість тієї чи іншої
помилки і визначити шлях її обробки. В Java для
цього передбачений спеціальний механізм винятків.
Коли
така ситуація виникає, створюється об'єкт, який передається ("вкидається")
в метод, в якому виникла помилка. Далі в методі цей виняток може оброблятися
або бути переданий ще кудись для обробки. Розглянемо
для прикладу наступну програму DivZero.java
Як
бачимо, в програмі присутнє ділення на нуль. При компіляції ми не отримаємо
помилок. Проте
після запуску програми отримаємо наступне:
Це
так звана траса стеку викликів. Перший рядок означає тип винятку. Як бачимо,
тут маємо ArithmeticException з діленням на нуль.
Другий
рядок вказує, де саме відбулась виняткова ситуація: 4-й рядок у файлі DivZero.java в методі main() класу DivZero. При цьому, як
бачимо, програма завершила своє виконання аварійно. Для уникнення цього існує
відповідний механізм обробки винятків, який дозволяє перехопити виняток,
одержати інформацію про нього, обробити його, здійснивши певні дії для
нормального закінчення або продовження виконання програми. Усі
типи винятків є підкласами класу Throwable, який входить у базовий пакет класів Java – java.lang. Тобто він є вершиною ієрархії класів винятків.
Його два підкласи Error та Exception утворюють дві основні гілки винятків.
Гілка
класу Exception – це винятки, які програма
повинна вловлювати (catch). Від цього класу
та його підкласів можна утворювати власні підкласи. Важливим його підкласом є
клас RuntimeException. Винятки такого типу включають ділення на нуль та
помилкову індексацію масивів. Актуальну
ієрархію класів винятків можна подивитися і уточнити в офіційній документації
до JDK. Для
обробки виняткових ситуацій використовується п’ять ключових слів: try, catch, throw, throws та finally. Інструкції
програми, в яких може виникнути помилка, контролюються за допомогою
конструкції try. Загальна
форма наступна:
Після
інструкції try ми розміщуємо "небезпечний" код, у блоці catch відбувається
обробка винятку, причому може бути кілька інструкцій catch.
Завершувати конструкцію може інструкція finally, в ній розміщується
код, який буде виконаний після обробки винятку в інструкції catch.
Результат
виконання: Ділення на нуль! Продовження
виконання... Як
бачимо, для перехоплення винятку код, через який виникала помилка,
знаходиться у середині конструкції try. Також зверніть
увагу, що після виникнення виняткової ситуації наступний рядок System.out.println("medium="+medium);
не було виведено, оскільки виняток був переданий для обробки в catch. Після інструкції
програми, в якій відбулась виняткова ситуація, всі наступні рядки до
інструкції catch пропускаються і не будуть
виконуватись. І, як бачимо з результату виконання, наша програма продовжила
виконання після закінчення блоку try, а не завершила
своє виконання аварійно. За
використання всередині try певних ресурсів,
наприклад, файлів, при виникненні винятку необхідно було передбачити закриття
відкритих ресурсів. Для цієї мети раніше приходилося використовувати блок finally.
У Java 7 з'явилася конструкція try
з ресурсами (англ. try-with-resources). Тепер просто можна створити ресурс у дужках зразу
ж після ключового слова try і Java
сама потурбується про закриття ресурсу. Приклад:
В
наведених вище прикладах ми здійснювали лише обробку винятків, викинутих
виконавчим середовищем Java. Проте існує можливість викидання власних винятків.
Для цього існує інструкція Throw. Загальна
форма її наступна:
Щоб
програма викинула ваш виняток, необхідно скористатися оператором new.
Для того, щоб одержати (перехопити) тип винятку, можна скористатися
інструкцією catch, як це ми робили
вище. Після
інструкції throw відбувається аналогічне породження винятку як у
вищенаведених прикладах. Тобто усі інструкції пропускаються до найближчого блоку
інструкції catch, де необхідно
здійснити обробку винятку. Якщо catch не буде знайдено,
то обробник винятків, що використовується за замовчуванням, призупиняє
виконання програми і друкує відбиток стеку (stack
trace). Приклад:
Результат: Наш виняток: java.lang.NullPointerException: Пробний виняток Програма
демонструє як створювати один із стандартних винятків. Більшість вбудованих runtime-винятків Java мають щонайменше два конструктори. Один за
замовчуванням без параметрів і один із параметром String, який дозволяє задати додатковий опис. Опис можна
вивести на консоль за допомогою методів print(), println(). Також його можна отримати, використавши метод getMessage() класу
Throwable. Можна
створити власний тип винятку як підклас уже існуючого типу. Якщо
метод породжує виняток і не обробляє його, то він повинен вказати про це, щоб
обробка винятку була здійснена у місці виклику цього методу. Це здійснюється
за допомогою застереження throws в оголошенні
методу. Після нього вказуються підряд через кому усі винятки, які можуть бути
викинуті методом, окрім винятків класів Error
та RuntimeException і їхніх підкласів.
Нагадаємо, що клас Error – це необроблювані
винятки, RuntimeException – винятки, які
виникають в результаті помилки програміста (вихід за межі масиву, нульове
посилання, невірне перетворення типів). Інші винятки – це помилки доступу,
які доволі часто вимагають відповідної обробки. Загальна
форма оголошення методу наступна:
Результат: Всередині
ExceptionMethod(). Наш
виняток: java.lang.IllegalAccessException: Помилка доступу Як
бачимо, тепер обробка винятку відбувається у методі main().
Без інструкції try-catch програма призупинятиметься з друком відбитку стеку.
Слід зауважити, що у методах інструкція throw
поводить себе подібно до інструкції return. Тобто виконання методу припиняється і відбувається
повернення в місце виклику методу.
За
об’єктно орієнтованого програмування доводиться працювати з великою кількістю
об’єктів. Зручно мати засоби групування об’єктів. З цією метою в Java розроблено набір інтерфейсів і класів на їх основі
під назвою колекції. В основі ієрархії колекцій
знаходиться інтерфейс Collection. Згадаймо,
що інтерфейс
не містить реалізації методів, а лише їхні оголошення. Можна реалізувати
безліч реалізацій інтерфейсу. Програмісту, який використовуватиме ці
реалізації, достатньо знати базовий інтерфейс для роботи з його реалізаціями,
тобто знати методи, які він передбачає.
Окремо
виділяють ще інтерфейс Map. Він не походить
напряму від інтерфейсу Collection, проте його також
відносять до колекцій. На їх основі створено набір класів, які згодяться
програмістам для більшості випадків роботи з набором об’єктів. Тож вам не
прийдеться самим їх реалізовувати. Якщо
вам цікаво, для чого стільки різних класів в колекціях? Суть в тому, що різні
класи по-різному реалізовують роботу з даними. Одні класи швидше здійснюють
читання даних, інші – вставлення і видалення, одні перевіряють, щоб не було дублювань, інші дозволяють вставляти дані за певним
ключем і т.д. Доволі важливо підібрати клас, який
найкраще підходить для вашого завдання і забезпечить найбільшу швидкодію.
Особливо це актуально, коли кількість об’єктів величезна. Клас
ArrayList призначений для читання
об'єктів за індексом. Тож недарма у назві є слово Array (масив).
Після створення колекції на основі ArrayList прочитати дані
можна кількома способами. Наступний приклад демонструє створення ArrayList, його наповнення об'єктами типу
String та їх читання за допомогою
методу get (int index) та за допомогою ітератора.
Результат: Привіт тобі
божевільний світе! Привіт тобі божевільний світе! Крім
вищенаведених способів, можна передати вміст ArrayList у звичайний масив
за допомогою методу toArray(). Якщо ви хочете детально розібратися з ArrayList і його методами, то для цього
також дивіться інформацію про інтерфейси Collection, List та Iterator. Окремо
розглянемо перегляд даних з допомогою ітератора.
Таким
чином створюється об’єкт ітератора, посилання на
який передається об'єктній змінній it типу ListIterator. ListIterator – це інтерфейс, який розширює інтерфейс Iterator декількома новими методами.
Різниця
між ArrayList та LinkedList полягає в тому, що ArrayList реалізований у
вигляді масиву, а LinkedList у вигляді пов’язаних між собою об’єктів. ArrayList швидко виконує читання і заміну елементів (посилань
на об’єкти), проте, щоб вставити новий елемент в середину ArrayList або видалити існуючий, в
середині ArrayList здійснюється послідовний зсув цілого
ряду елементів масиву. В LinkedList доволі швидко
відбувається вставлення нового елементу або видалення існуючого. Це
відбувається тому, що в середині реалізації LinkedList змінюються лише посилання на попередній і наступний
об’єкти (елементи). Проте доступ до об’єктів за індексом в LinkedList відбувається повільніше, ніж в ArrayList. Тож загалом, LinkedList корисний, коли необхідно часто
вставляти та видаляти елементи зі списку, а в інших випадках краще
використовувати ArrayList.
Перший
конструктор створює пустий список, а другий – створює пов’язаний список із
іншої колекції. Клас LinkedList розширює клас AbstractSequentalList
та реалізує інтерфейси List, Dequeue та Queue.
Реалізація останніх двох інтерфейсів (черг) означає, що ми можемо працювати
із пов’язаним списком як із стеком з використанням
методів pop(), push(), poll(), pollFirst(), pollLast() та ін. Детальніше дивіться документацію за заданими
інтерфейсами.
Якщо
потрібна впорядкована множина, то використовуйте TreeSet. HashSet також
не гарантує стабільного порядку збереження об’єктів. Тобто при додаванні
об’єктів порядок зберігання елементів змінюється. Вони можуть бути збережені
як в кінці множини, так і в середині. Якщо потрібен один порядок зберігання
об’єктів, використовуйте LinkedHashSet. Сам
термін "множина" означає, що елементи не будуть повторюватися. Для
зберігання і пошуку елементів використовується хеш-код об’єкта. HashSet також може містити значення null.
Власне всередині самої реалізації HashSet використовується
клас HashMap, який дозволяє
зберігати елементи у вигляді двох складових ключа та хеш-коду. У класі HashSet
хеш-код недоступний і використовується неявно для користувача. Клас
HashSet розширює клас AbstractSet та реалізує інтерфейс Set.
Також реалізовує інтерфейси Serializable та Clonable. Клас
LinkedHashSet розширює клас HashSet, не додаючи ніяких нових методів. Працює він дещо
довше за HashSet, проте зберігає
порядок, в якому елементи додаються до нього. Відповідно це дозволяє
організувати послідовну ітерацію вставлення та витягнення елементів. Всі
конструктори та методи роботи з LinkedHashSet аналогічні методам класу HashSet. Клас
TreeSet дозволяє
створювати відсортовану множину. Тобто елементи не повторюються та
зберігаються у відсортованому порядку. Для зберігання елементів
застосовується бінарна деревоподібна структура. Об'єкти зберігаються у
відсортованому порядку та за зростанням. Час доступу та одержання елементів
доволі малий, тому клас TreeSet підходить для
зберігання великих об’ємів відсортованих даних, які повинні бути швидко
знайдені. Клас
TreeSet розширює клас AbstractSet
та реалізує інтерфейс NavigableSet. NavigableSet
реалізується на базі TreeMap. Ранні
версії Java не включали структуру Collections. Там було визначено декілька
класів та інтерфейсів, що надавали методи для зберігання об'єктів. Структура Collections була додана в Java 2 (j2se 1.2). Тоді початкові класи були перероблені для
підтримки інтерфейсів колекцій. Ці ранні класи також знані як успадковані
класи (Legacy classes). В
Java 5 успадковані класи та інтерфейси були
перероблені для підтримки узагальнень. Їх підтримують, тому що й досі існує
код, який їх використовує. Успадковані класи – синхронізовані. Класи входять
в пакет java.util.
Успадкованим
є інтерфейс Enumeration,
на заміну якому прийшов інтерфейс Iterator. Enumeration інтерфейс
й досі використовується в кількох методах класів Vector та
Properties. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||